
Video
Abstract
Visual-language models (VLMs) have recently been introduced in robotic mapping by using the latent representations, i.e., embeddings, of the VLMs to represent the natural language semantics in the map. The main benefit is moving beyond a small set of human-created labels toward open-vocabulary scene understanding. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is missing. In this paper, we propose a way to analyze the quality of maps created using VLMs by evaluating two critical properties: queryability and distinctness. We demonstrate the proposed method by evaluating the maps created by two state-of-the-art methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set.
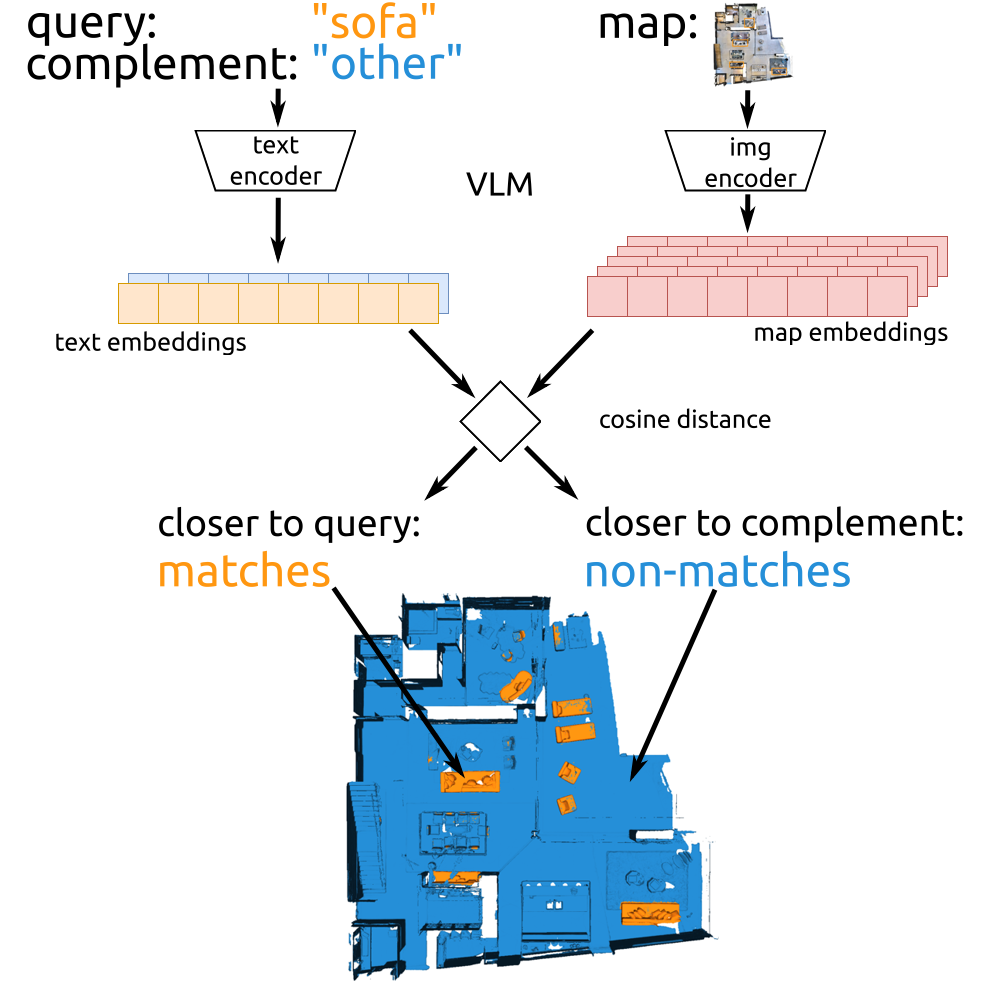
Queryability
Method
- Captures the ability to retrieve information from the embeddings.
- The hypothesis is that from a map with high queryability, it is possible to find accurate matches to a wide range of queries.
- We compare with semantic segmentation.
Results
| Method | Encoder | Segmentation | Querying | ||
|---|---|---|---|---|---|
| F1 | IoU | F1 | IoU | ||
| OpenScene | LSeg | 0.645 | 0.480 | 0.174 | 0.095 |
| OpenScene | OpenSeg | 0.603 | 0.435 | 0.111 | 0.059 |
| VLMaps | LSeg | 0.541 | 0.375 | 0.425 | 0.271 |
| VLMaps | OpenSeg | 0.495 | 0.333 | 0.367 | 0.226 |
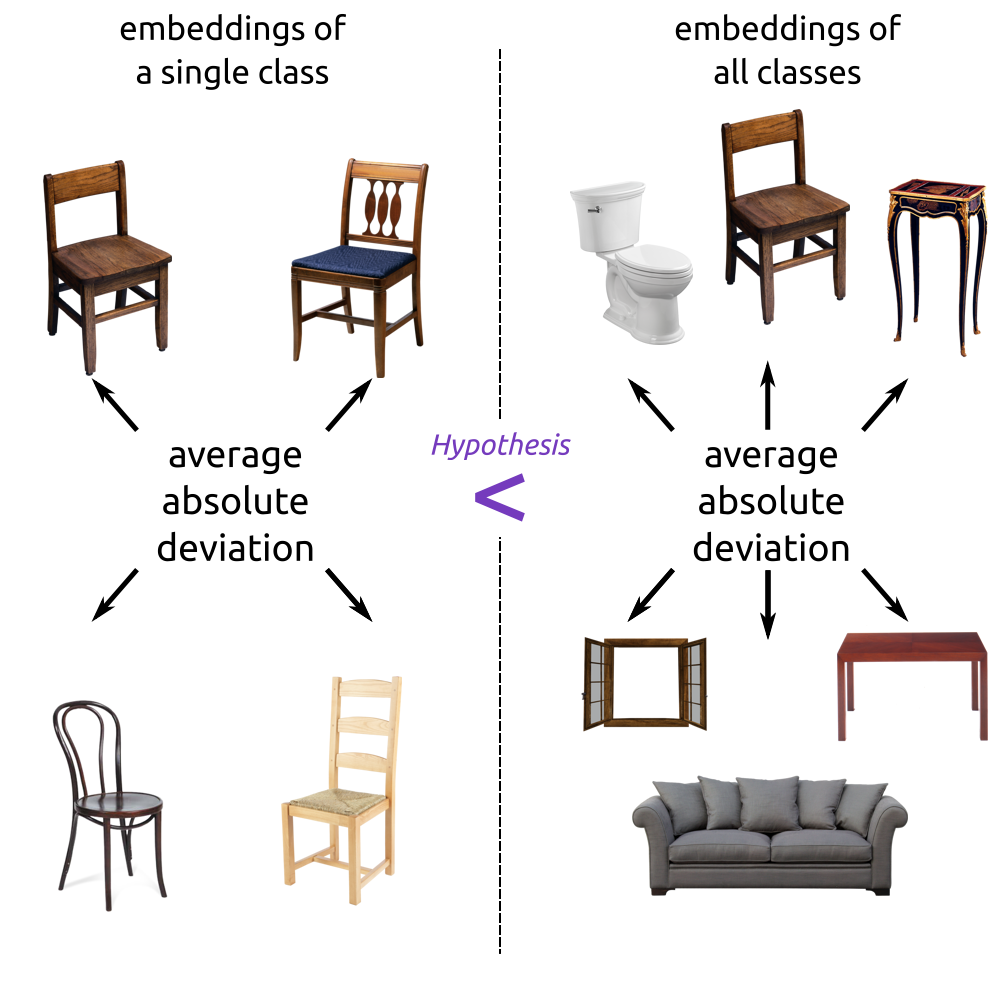
Intra-map distinctness
Method
- Captures the similarity of embeddings with the same semantic label within a single map.
- The hypothesis is that embeddings sharing semantic meaning are clustered together in the latent space, allowing the distinguishing of different concepts.
Results

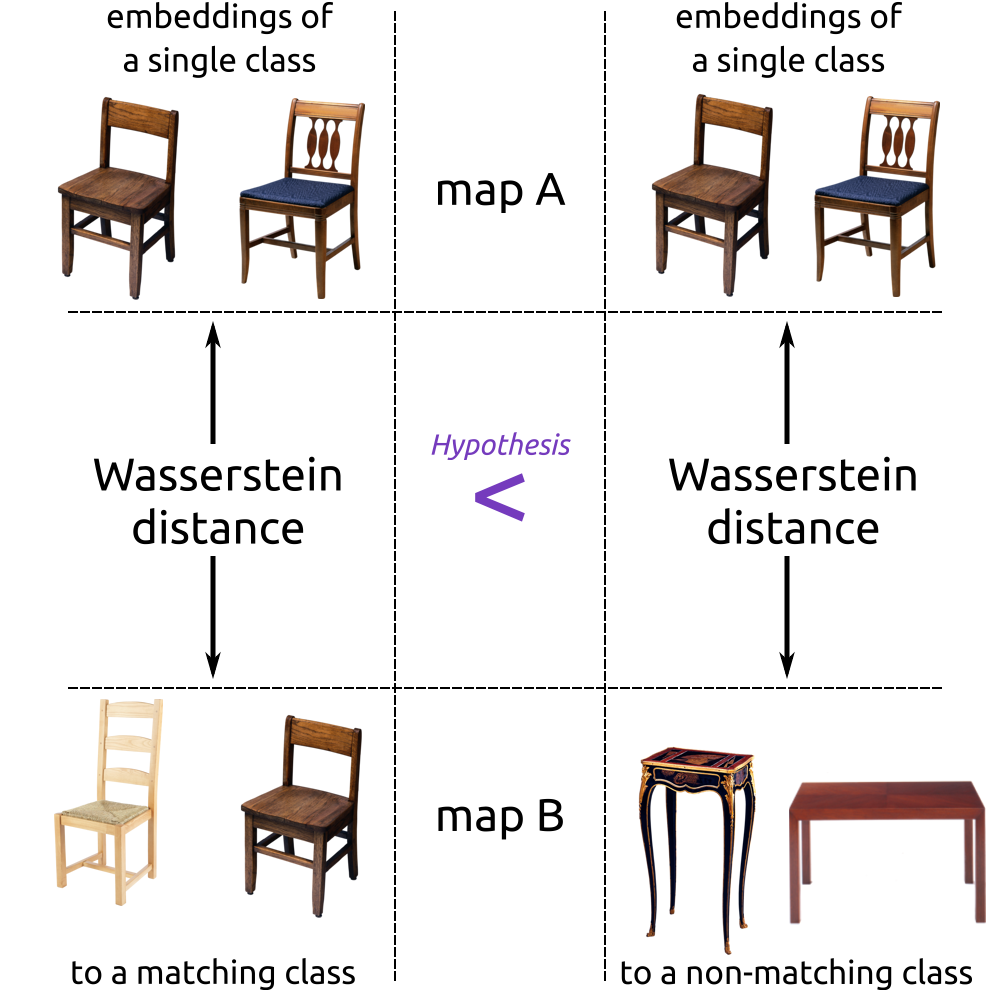
Inter-map distinctness
Method
- Captures the similarity of embeddings with the same label across different maps.
- The hypothesis is that embeddings within the same label are closer to each other across maps than to those with different labels, therefore retaining their distinctness across maps.
Results

Resolution
- We evaluate the effect of the grid map resolution by performing the semantic segmentation experiment on a range of cell sizes.

Conclusion
- 3D features used by OpenScene increase queryability. OpenSeg has the best results in the semantic segmentation task.
- Unlike image features, 3D features are not scale invariant. This means that a 3D network has to be trained for each resolution, making image-based methods more versatile.
- The choice of encoder matters. LSeg performed better than OpenSeg with both methods in all of our experiments.
- Open-vocabulary queryability is still an open problem. Currently, fully supervised semantic segmentation methods outperform all latent-semantic maps. The open-vocabulary querying method, proposed in VLMaps, cannot sufficiently partition the environment, yielding poor results.
- While we were limited in our quantitative evaluation of closed vocabulary, all the proposed metrics can be extended to open vocabulary.
Citation
If you find this work useful, please consider citing:
@inproceedings{pekkanen_2025_latent_semantics,
title={Do Visual-Language Grid Maps Capture Latent Semantics?},
author={Pekkanen, Matti and Mihaylova, Tsvetomila and Verdoja, Francesco and Kyrki, Ville},
booktitle={2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher={IEEE},
year={2025},
month={October},
address={Hangzhou, China},
volume={},
number={},
pages={4059--4066},
keywords={Measurement;Vocabulary;Three-dimensional displays;Image resolution;Accuracy;Navigation;Semantic
segmentation;Semantics;Pipelines;Intelligent robots},
doi={10.1109/IROS60139.2025.11247447}}
}
Acknowledgements
This work was supported by Business Finland (decision 9249/31/2021), the Research Council of Finland (decision 354909), Wallenberg AI, Autonomous Systems and Software Program, WASP and Saab AB. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPUs used for this research.