Video
The problem
- VLM embeddings are increasingly used as semantic descriptors in maps.
- The key challenge is querying the embeddings.
- State-of-the-art methods based on thresholding distances or using a single complementary query are insufficient for visual classification.
The solution
- Training a classifier on text-description embeddings yields a good classifier in the visual domain, because textual descriptions and visual features are embedded in the same space.
- QuASH uses a heuristic of natural-language synonyms and antonyms associated with the query to train a classifier in the embedding space.
Method
To find the target set related to a query q in the visual space:
- Sample semantically similar words to q to form a query set, and sample non-matching queries in language space.
- Embed the matching and non-matching query sets with the text encoder.
- Train an off-the-shelf classifier in the shared embedding space.
The decision boundary of the classifier yields the estimated region of embeddings that match the query.

Results: Image querying
SheepRefrigeratorPersonSkateboard
Original



 Ours
Ours



 Baseline
Baseline




Ours
Baseline
| Dataset | Method | F1 | P | R |
|---|---|---|---|---|
| COCO | baseline | 0.680 | 0.536 | 0.929 |
| Our SVM | 0.786 | 0.696 | 0.901 | |
| Our C-SVM | 0.771 | 0.672 | 0.905 | |
| PC 459 | baseline | 0.654 | 0.540 | 0.831 |
| Our SVM | 0.667 | 0.693 | 0.643 | |
| Our C-SVM | 0.728 | 0.680 | 0.783 | |
| Matterport | baseline | 0.544 | 0.448 | 0.691 |
| Our SVM | 0.621 | 0.626 | 0.616 | |
| Our C-SVM | 0.579 | 0.483 | 0.724 |
Results: Map querying
ChairShelvingWallTable
Ours


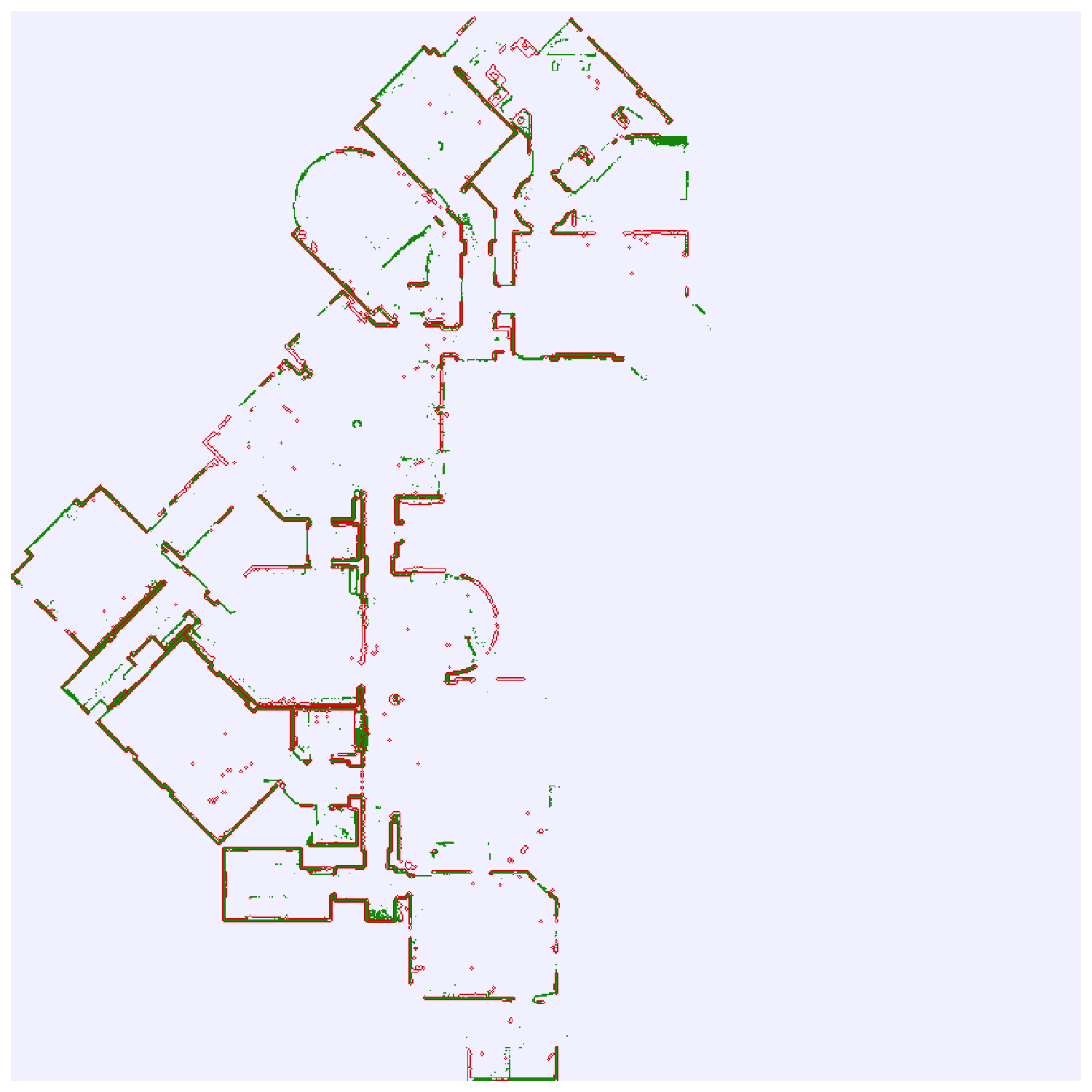
 Baseline
Baseline

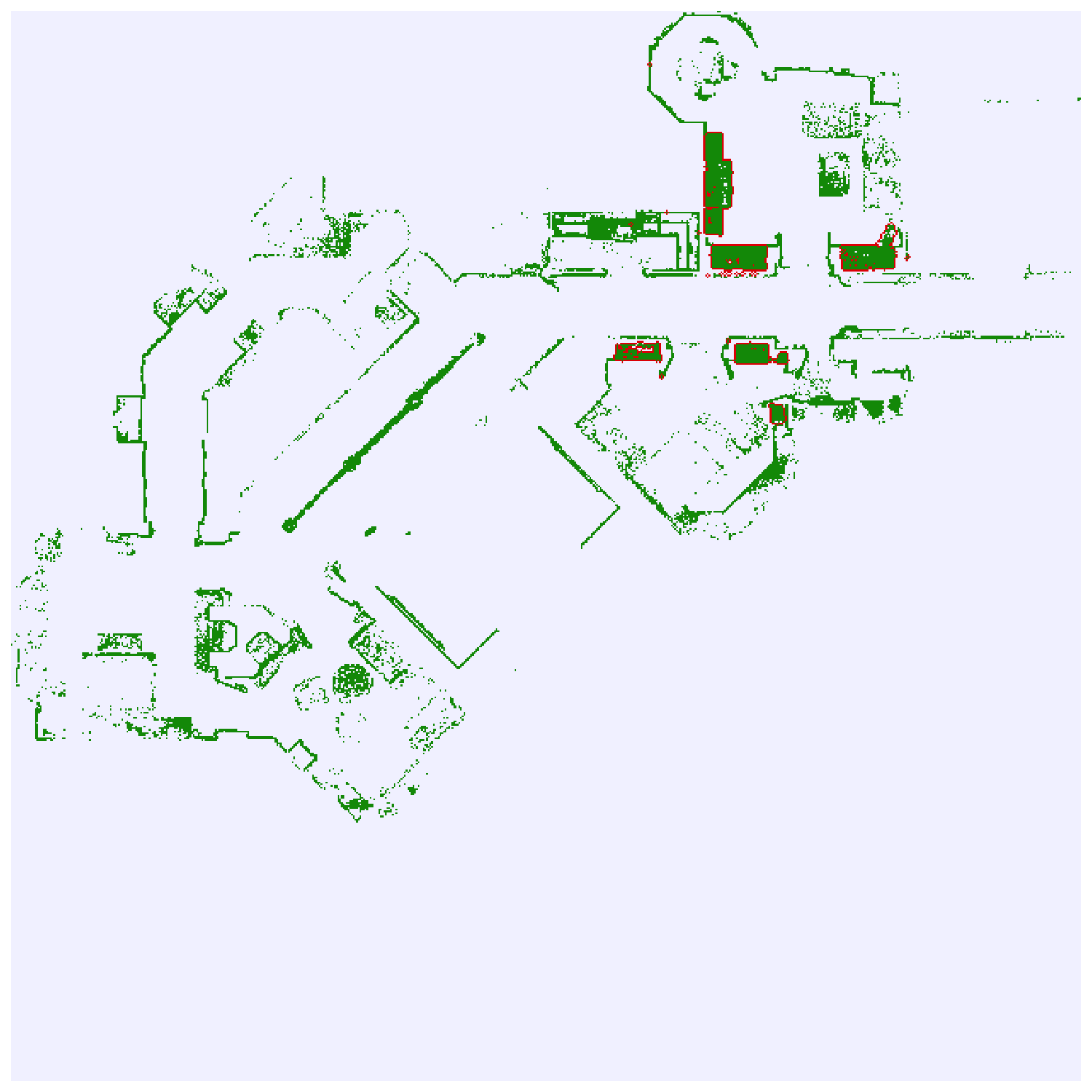
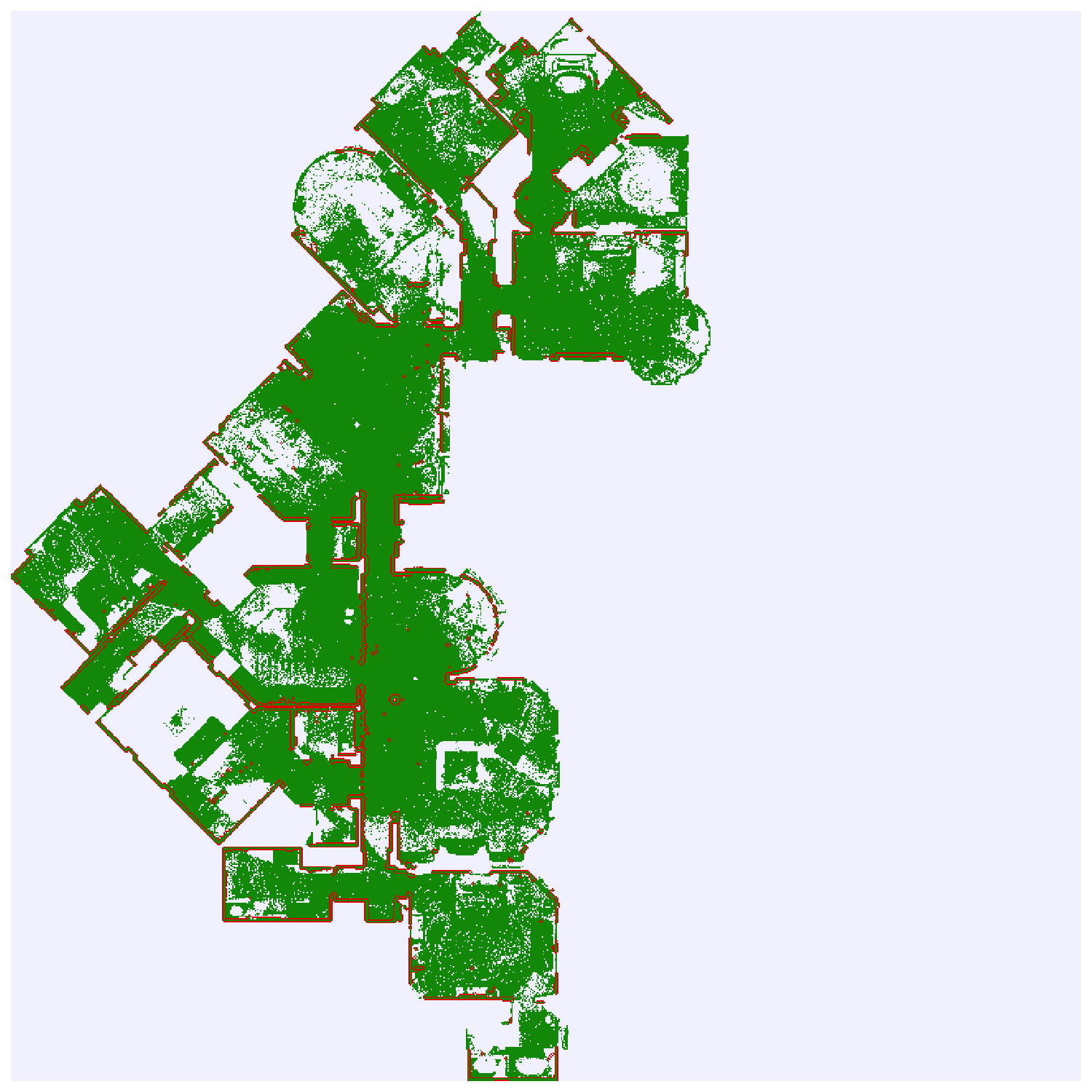
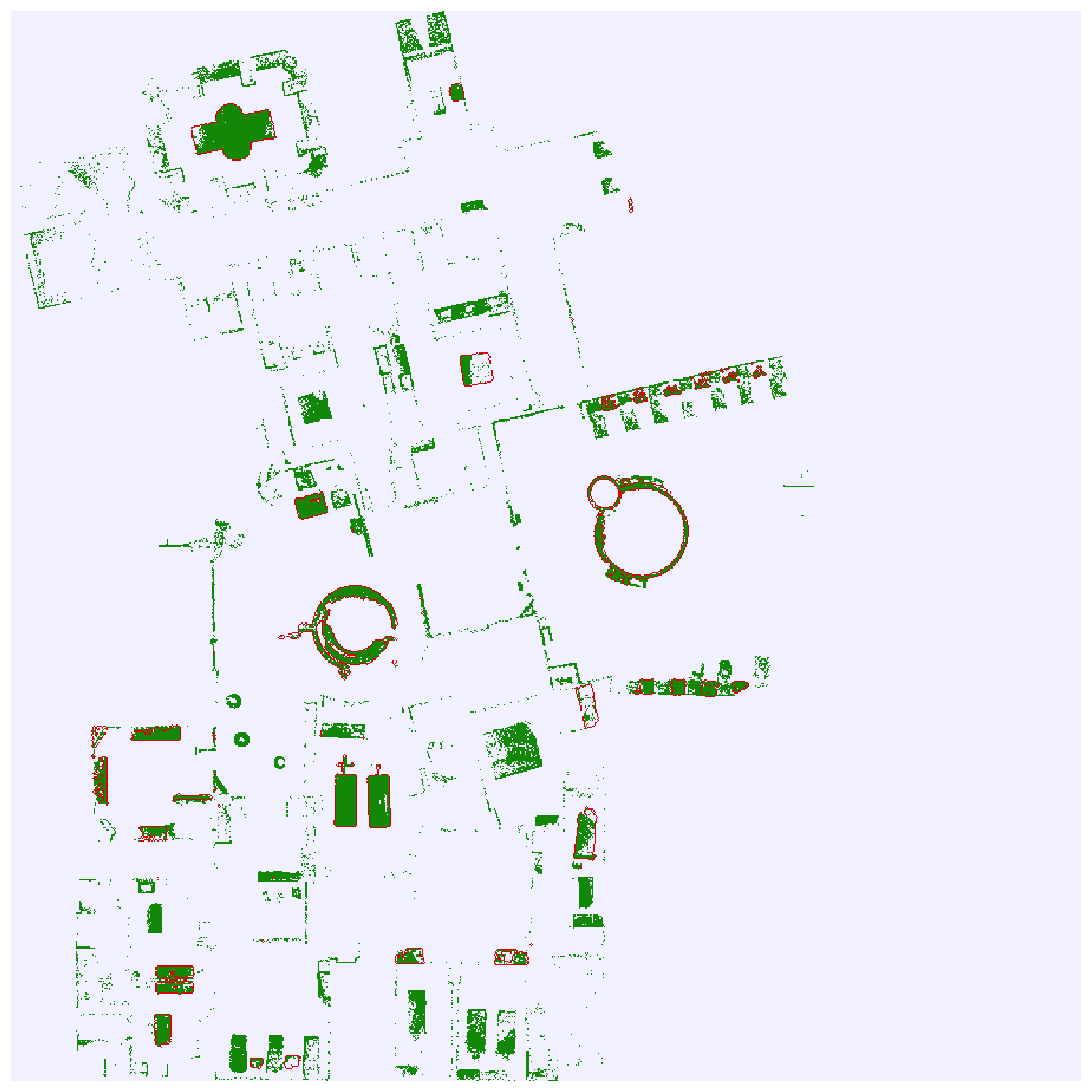
Baseline
| Encoder | Method | F1 | P | R |
|---|---|---|---|---|
| LSeg | baseline | 0.561 | 0.536 | 0.589 |
| our ground truth | 0.574 | 0.567 | 0.583 | |
| our LLM | 0.396 | 0.289 | 0.656 | |
| OpenSeg | baseline | 0.136 | 0.073 | 0.926 |
| our ground truth | 0.445 | 0.622 | 0.369 | |
| our LLM | 0.242 | 0.154 | 0.586 |
Conclusion
- QuASH has a higher F1-score in all image experiments.
- QuASH has the highest F1-score in map experiments with ground-truth synonyms.
- QuASH has a higher F1-score in map experiments when using OpenSeg with any heuristic.
- Leveraging semantic knowledge to heuristically sample from language space improves visual classification when the query-distribution approximation is good.
Citation
If you find this work useful, please consider citing:
@inproceedings{pekkanen_2026_quash,
title = {{QuASH: Using Natural-Language Heuristics to Query Visual-Language Robotic Maps}},
author = {Pekkanen, Matti and and Verdoja, Francesco and Kyrki, Ville},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2026},
month = {May},
address = {Vienna, Austria},
publisher = {IEEE},
pages = {XX--YY},
doi = {XXX}
}